
Implementing Causal Consistency
Posted: May 27, 2014 Filed under: Uncategorized | Tags: causal consistency, eventual consistency, replication models Leave a commentIn my previous post, I discussed how to implement bounded staleness. Today, I focus on techniques for implementing causal consistency. Causal consistency appears to be popular in the academic research community, but not as popular in the commercial world. In theory, it makes perfect sense. But there’s a lot to grasp both in understanding the consistency guarantee and in implementing it efficiently in a replicated storage system.
What is causal consistency?
In short, Reads and Writes are partially ordered according to the happens-before relationship (as defined in Leslie Lamport’s seminal paper). Imagine a graph in which the nodes are Read and Write operations and there is a directed edge from node A to node B if node A causally precedes node B. A Read operation in this graph sees the effect of any Write operation for which there is a directed path from the Write’s node to the Read’s node.
I find it useful to break out three key properties:
1. Writes are causally ordered.
Example 1: A client performs Write(A) followed by Write(B). Write(B) happened after Write(A), and hence should be ordered after it in all replicas. “Write(A) < Write(B)” denotes that Write(A) causally precedes Write(B).
Example 2: A client at site 1 performs Write(A), then sends a message to site 2. After receiving this message, a client at site 2 then performs Write(B). Again, Write(A) < Write(B).
2. Reads are causally ordered.
Example 3: A client performs Read(A) followed by Read(B). Clearly, Read(A) < Read(B).
Example 4: A client at site 1 performs Read(A) and then sends a message to site 2. A client at site 2 then performs Read(B). Again, Read(A) < Read(B).
3. Reads see writes in causal order.
Example 5: A client performs Read(B) and sees the effect of Write(B) which may have been performed by a different client. Write(B) causally precedes Read(B), i.e. Write(B) < Read(B). Suppose that Write(A) causally precedes Write(B). If this client now performs Read(A), it should see the effect of Write(A) since Write(A) < Write(B) < Read(B) < Read(A).
Example 6: A client at site 1 performs Read(B) and sees the effect of Write(B) which causally follows Write(A). It then sends a message to site 2. A client at site 2 then performs Read(A). This client should see Write(A) since Write(A) < Write(B) < Read(B) < Read(A).
Some systems, such as the COPS paper from SOSP 2011 and my Pileus paper from SOSP 2013, redefine causal consistency in order to provide a practical implementation. In particular, these systems assume that clients only communicate through the storage system (thereby eliminating Examples 2, 4, and 6 above). Read and Writes performed by the same client are ordered, of course, by the order in which they are performed (as in Examples 1 and 3). Additionally, a Read operation is ordered after any writes whose effects are visible to the read (as in Example 5). Let’s call this “read/write causal consistency”.
How can a system provide read/write causal consistency?
COPS arranges replicas into clusters, where each cluster resides in a single datacenter. Writes within a cluster are strictly ordered, resulting in linearizability (a stronger property than causal consistency). Causal ordering between Writes are tracked by the client library in the form of dependencies. Writes, when lazily propagated between clusters, carry their dependencies with them. A cluster only commits a Write when all of its dependencies have already been committed in that cluster. This ensures that replicas within each cluster remain causally consistent. Reads are allowed to access only a single cluster. This ensures that readers see a causally consistent system.
Pileus takes a different approach, one that does not require explicit dependency tracking and that does permit a client to read from different replicas in different datacenters. Primary update schemes, as used in Pileus, automatically order Writes in causal order (since they are strictly ordered by when they are performed at the primary). Each secondary replica in Pileus is causally consistent since replicas receive writes in order, i.e. in causal order. The only complication then is ensuring causal consistency when a client performs reads at different secondary replicas over time. For instance, a client is not allowed to read version V2 of some object from one replica and then later read version V1 from another replica.
Each client simply records all of the version timestamps for objects returned by its Read operations and all of the version timestamps produced by its Writes. When performing a Read operation with a given key, the client computes the minimum acceptable read timestamp for this operation. This timestamp is the max of all previous Reads by the client for any key and previous Writes for the same key. The client can then read from any replica whose high timestamp (the maximum version timestamp of all Writes received by that replica) is greater than the minimum acceptable read timestamp; any such replica is sufficiently up-to-date.
Consider the Example 5 given above. Suppose the client performs Read(B) and it returns a version of object B with timestamp 42. When the client then performs Read(A), it sets the minimum acceptable read timestamp to a value no less than 42. This guarantees that this Read(A) will be performed at a replica that already holds the latest version of object A with a timestamp less than 42. Since Write(A) causally preceded the Write(B) whose version was previously returned to the client, we know that it produced a version of object A with a timestamp less than 42. Using the minimum acceptable read timestamps correctly ensures that the client will read this version of A (or perhaps a later version).
However, the use of minimal acceptable read timestamps, while avoiding dependency tracking, has a downside. It leads to pessimistic assumptions about causal dependencies, and hence to overly conservative replica selection. In this same example, suppose that Write(A) and Write(B) were not causally related. For instance, they may have been performed by different clients with no interleaving Reads. In this case, when the client performs Read(A), it could receive any version of object A without violating causal consistency. The client could read from any replica, including ones that hold arbitrarily stale versions. But, Pileus has no way of determining whether versions of A with timestamps less than 42 causally precede version 42 of object B (since it records no dependencies). Essentially, Pileus pessimistically assumes that all Writes are causally related and causally ordered according to their version timestamps.
This technique produces correct behavior when there is a single primary. When data is sharded across multiple primaries that independently assign version timestamps, potential problems may arise. Consider our same Example 5 in which Write(A) causally precedes Write(B) but keys A and B are mastered at different primaries with different clocks. It is possible for Write(B) to produce a version of B with timestamp 42 while Write(A) produced a version of A with a larger timestamp (maybe because A’s clock is faster than B’s or because timestamps are drawn from an update counter and A has accepted more Writes). Now, setting the minimum acceptable timestamp to 42 does not ensure causal consistency. The client could possibly read an old version of object A, say with timestamp 21.
To avoid this problem, the primaries need to maintain logical clocks so that all Writes are causally ordered. That is, when a client performs a Write operation for a given key, it informs the responsible primary replica of the timestamp of the client’s latest preceding Write. The new Write is then assigned a larger version timestamp. This solves the correctness problem identified above in a simple way, and it does not require explicit tracking. It still leads to pessimistic assumptions about causal dependencies.
In summary, there are two ways to implement causal consistency. One is to explicitly record causal dependencies between Reads and Writes. This permits optimal replica selection, but takes space for storing the dependency information and leads to complicated procedures for garbage collecting this information. The second approach, which I prefer, is to use timestamps as described above, which avoids the need for explicit dependency tracking. But this can lead to overly pessimistic replica selection with the associated performance consequences.
Implementing Bounded Staleness
Posted: April 17, 2014 Filed under: Uncategorized | Tags: bounded staleness, eventual consistency, staleness Leave a commentOne of the consistency choices that Pileus supports is bounded staleness, which guarantees that the version returned by a read operation is no more than t seconds out-of-date. In other words, if the latest version was produced more than t seconds ago, then the reader is guaranteed to receive it; if the object was updated in the last t seconds, then the reader may or may not receive the latest version, but, in any case, is guaranteed to at least receive the version that was the latest as of t seconds ago. The first paper to mention such a staleness guarantee, as far as I know, is “Data Caching Issues in an Information Retrieval System” by Alonso, Barbara, and Garcia-Molina (ACM Transactions on Database Systems, September 1990).
The simple way to implement bounded staleness, assuming a primary update scheme, is as follows. Each secondary replica periodically syncs with the primary and records the time of its last sync. A client reading data can determine whether a secondary replica is sufficiently up-to-date by (1) subtracting the desired staleness bound from the current time to get an acceptable read time and (2) then checking whether the resulting acceptable read time is earlier that the replica’s last sync time. That is, a replica can serve the read request while meeting the bounded staleness guarantee as long as the replica has synchronized directly (or indirectly) with the primary sufficiently recently.
Note that this is a pessimistic implementation since it may disallow reading from replicas that are, in fact, sufficiently up-to-date for the object being read. For example, many objects are written once and never again updated. Suppose that the latest version of the object being read was produced months ago, then it could be read from any replica while guaranteeing any reasonable staleness bound. Unfortunately, clients cannot assume anything about update patterns. Thus, they make pessimistic decisions about suitable replicas based on the last sync times (or else they would need to contact the primary to discover the timestamp of the latest version, which reduces the benefit of reading from secondary replicas).
However, this implementation technique assumes (a) that the client’s clock is loosely synchronized with those of the servers, and (b) that the servers report their last sync times. Neither of these are generally good assumptions. Consequently, we developed a different way of enforcing bounded staleness in the Pileus system.
In Pileus, servers use logical clocks. Thus, the timestamps that are assigned to versions and the high timestamps that are maintained and reported by servers are not directly useful for determining those servers that can meet a staleness bound. However, here’s a client-side technique that works.
Each client maintains a mapping from real time (according to the client’s clock) to logical time (according to the primary server’s logical clock). Specifically, whenever a client accesses the primary server to perform a Get or Put operation, the server returns its current high timestamp (as a logical clock value). The client records its current time, taken from the local real-time clock, along with the server’s high timestamp. To get a conservative but usable mapping, the client records its clock at the start of the Get request rather than at the receipt of the response (or it could measure the round-trip time and choose the mid-point of the time interval as in some clock synchronization algorithms). This mapping is a little off due to the message transmission delay, but that should be a small amount relative to staleness bounds.
This mapping table need not be large since it does not need to record every interaction with the primary. One entry per minute, for instance, is probably sufficient. Basically, it needs to cover the range of times that are likely to be mentioned in a staleness bound and in sufficient granularity. Older entries in the table can be discarded once their logical timestamps fall below the minimum high time of all servers (or all servers that the client is likely to access, such as those that are closer than the primary).
To determine which servers can meet a staleness bound, the client computes the minimum acceptable read time = now – bound. The client then looks up this timestamp in its table to find the associated logical time. It uses the next highest recorded time as an approximation. For example, suppose that the client has entries for 8:00 and 8:05, but wants a read time of 8:03; it can use the 8:05 entry as a conservative bound. The client then chooses from among the servers with a high timestamp that is greater than the recorded logical time.
Consider a scenario in which a client wants bounded staleness with a bound of 5 minutes and ideally would like to read from its local server. Suppose this client knows that the local server is currently less than 5 minutes out-of-date. This client can perform all of its reads locally. This client can also ping the primary once per minute to retrieve its current logical high time (or piggyback such pings on regular write operations). If the local server syncs with the primary frequently enough, say once every few minutes, and the client performs reads frequently enough, then the client would get the local server’s high time in response to a read operation and always determine that the local server was okay for its next read. If the local server syncs too infrequently, say once every 15 minutes, then the client would eventually discover, based on its local mapping table, that the local server it too out-of-date. At this point, it would need to switch to a different server, such as the primary. After the local server syncs with the primary, the client would notice this since it periodically pings the local server. The client could ten switch back to reading locally.
A key advantage of this scheme is that it assumes nothing about synchronized clocks. Each client maintains its own mapping table based on its own local clock, which could be arbitrarily out of sync. Such a technique would work even if servers used physical, but unsynchronized clocks.
A Pileus-on-Azure Demo
Posted: March 7, 2014 Filed under: Uncategorized | Tags: Cloud storage, eventual consistency, Microsoft, replication models, Windows Azure Leave a commentI just returned from Microsoft Research’s annual technology showcase (called “TechFest”). For two days, with my colleague Rama Kotla, I was talking about and demoing the Pileus-on-Azure system to people from all over Microsoft. It was fun, rewarding, and totally exhausting.
I showed a version of Pileus that runs on top of the Windows Azure Storage (WAS) key-value blob store. In particular, we use WAS storage accounts as our basic units of storage. Each such account replicates data on three servers within an Azure datacenter, which we call a “site”. Our Pileus-on-Azure systems adds four main features to the basic WAS functionality.
One, we allow a WAS blob container to be replicated on any number of sites throughout the world. Specially, data can reside in any Azure region, of which there are currently at least ten spread over Europe, Asia, and the United States. One (or more) of the storage sites is designated as the primary, and all updates are performed at that site (or set of sites). Other sites are considered secondary sites. These receive updates lazily from the primary site. The intention is to allow data to be placed near where it is being accessed for clients that can tolerate relaxed forms of consistency.
For my demo, I used two Azure accounts with the primary residing in the West Europe region and the secondary in the West US region. I turned on Azure’s geo-replication. So this actually caused the data to be replicated in four datacenters. The West Europe account geo-replicated its data to the North Europe region, and the West US account geo-replicated to the East US region. This configuration resulted in each blob fully residing on 12 different servers in four different datacenters in three different countries. Perhaps, that’s a bit much, but, hey, it’s a demo.

Two, Pileus-on-Azure supports six different consistency choices: strong consistency, causal consistency, bounded staleness, read my writes, monotonic reads, and eventual consistency. I described the semantics of these in an earlier blog post (and in my recent CACM article which was also mentioned in a previous blog post and, from what I learned at TechFest, is now required reading for some Microsoft product groups). In contrast, WAS provides strong consistency by default, but recently started allowing clients read-only access to geo-replicated sites, thereby providing the option of eventual consistency reads (similar to Amazon’s DynamoDB or other commercial cloud storage systems). The reason to offer consistency choices is because of the inherent trade-offs between the guarantees offered by a consistency choice and the performance of read operations.
In the demo, I ran a client on a local machine in the Microsoft Convention Center that was performing read and write operations in accordance with the YCSB benchmark using the Pileus-on-Azure API, which essentially is identical to the API provided by the WAS client library. This client would periodically trigger synchronizations between the primary site in West Europe and the secondary in West US. The following screenshot from the demo shows the measured average response time for read operations using each of the six consistency choices:

You can see that choosing strong consistency results in reads that are seven times slower than eventual consistency reads for our given configuration. The other consistency choices fall somewhere in between. Causal consistency is less than a third the cost of strong consistency in this case, but the results are very workload dependent; note that I improved the causal consistency implementation and so these numbers are much better than ones we reported in our SOSP paper for an earlier version of Pileus. For bounded staleness, I chose a bound of 30 seconds for this demo, meaning that readers receive data that is at most 30 seconds out-of-date; even with such a tight guarantee, bounded staleness improves the read performance by a factor of two compared to strong consistency. The read my writes guarantee, which application developers often desire, is only slightly more expensive than eventual consistency. Monotonic reads behave exactly the same as eventual consistency reads since they both always access the nearby West US site; there is no reason for monotonic reads to go anywhere else unless this site becomes unavailable.
Three, Pileus-on-Azure allows client applications to express their consistency and latency desires in the form of a consistency-based service level agreement (SLA). Each such SLA consists of a sequence of acceptable consistency/latency pairs with associated utilities (a numerical value between 0 and 1). Thus, clients are not locked into a single consistency choice. A consistency-based SLA governs the execution of each read operation. The Pileus-on-Azure client library attempts to maximize the utility that is delivered to the client by selecting the site(s) to which each read operation is sent.
In the demo, the performance numbers for each of the six consistencies were generated by using six simple SLAs containing a single consistency choice and unbounded latency. More interestingly, I ran the YCSB workload using what I call the “fast or strong” SLA. In this SLA, the client prefers strong consistency provided it can receive read results in under 150 ms. If not, it will accept weaker consistency, such as bounded or eventual, for a fast response. If a fast response is not possible, then the client will wait up to 2 seconds for strongly consistency data. In other words, the client does not want a slow, stale response. Here’s what this SLA looks like in the demo:

While meeting this SLA, the client sends all of the read operations to the local West US site since the primary in Europe is not able to respond in under 150 ms. This results in an average delivered utility of just over 0.5. The client mostly receives eventually consistency data but occasionally receives data that meets the bounded staleness condition, i.e. the read occasionally returns a version of the requested blob that is known to be stale by no more than 30 seconds. The client does receive fast response times, and obtains acceptable but probably disappointing overall utility. Which brings me to the fourth part of the demo.
Four, Pileus-on-Azure includes a Configuration Service that can automatically select where data should be replicated. Each client that shares a blob container reports (1) the SLA(s) that it is using, (2) the reads and writes that it performed recently, and (3) its measured round-trip latencies to each of the potential storage sites. The configuration service collects this information from clients and uses it to generate and evaluate possible alternative configurations. It suggests what sites should store replicas of the container, what site(s) should be the primary, and how often secondary sites should synchronize with the primary. It considers constraints, such as limits on the number or locations of replicas. It also has a cost model based on Azure’s pricing scheme and considers the cost of new configurations, both the one-time cost of moving from the current to a new configuration and also the ongoing replication costs. It proposes the configuration that is expected to maximize the overall utility to the clients per unit of cost. Note that this configuration service was not described in our prior SOSP paper; this is more recent work done with an intern, Masoud Saeida Ardekani.
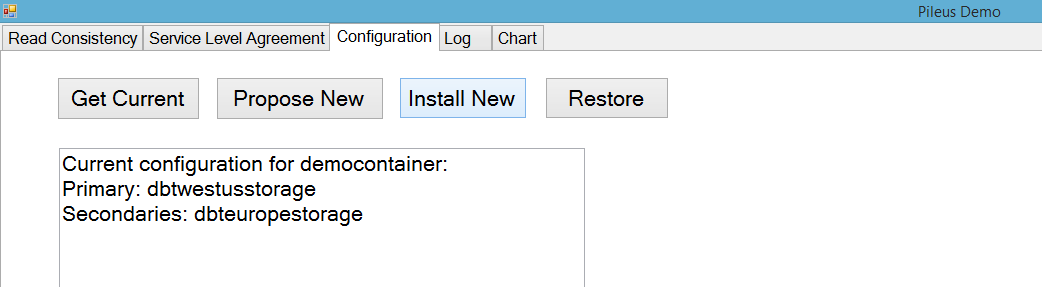
In the demo, I ask the configuration service to propose a new configuration. Not surprisingly, since throughout the demo there was only once client accessing the data, the configuration service makes the reasonable suggestion of moving the primary to the West US site. It also reports the expected gain in utility by changing to this new configuration and the expected cost. In this case, there is no increased cost since the number and location of replicas remains the same, with only the primary site changing:

When I click on the “Install New” button, the configuration service takes action. It first upgrades the West US site to a write-only replica so that this site receives new updates from clients. It forces a synchronization between West US and the current primary in West Europe so that the latest versions are in both places. Finally, it upgrades the West US site to be a read-write replica and downgrades the West Europe site to be a read-only secondary replica.
Now, in the demo, when I re-run the read-write-sync workload, you see that all of the consistency choices result in the same performance since they all read from the new West US primary (note that variations in the reported averages are caused solely by network and server load variations):

And, as expected, my “fast or strong” SLA delivers a utility of 1, meaning that the client always receives the top level of service:

That’s the demo! It ran for two straight days without crashing or experiencing any hiccups. Way to go Windows Azure! I can’t wait to see my Azure bill for this month.
The Impact of Eventual Consistency on Application Developers
Posted: September 27, 2013 Filed under: Uncategorized | Tags: eventual consistency, replication models, technology Leave a commentEventual consistency is commonly used in replicated cloud storage systems because it offers better performance and availability than strong consistency replication models. But, at what cost? Often I hear people say that eventual consistency places too great a burden on application developers. I hear that it results in more complicated code. However, I have seen little evidence of this and little written about this in the published literature. Let’s explore some of the potential costs of eventually consistent storage systems, with a particular emphasis on how it affects developers who store application data in such systems.
Data Access Paradigms
I see three broad patterns of how applications read and write their data: Read-Display, Read-Modify-Write, and Generate-Write. If you are aware of other widely used access patterns, please let me know.
Read-Display applications (or code segments) are those that retrieve data from a storage system and display it to their users. The data may be manipulated or transformed in some way before being displayed, but mostly is shown directly to users. Examples include social networking (e.g. Facebook, Foursquare, Twitter), photo sharing (e.g. Flickr), and news reading (e.g. New York Times online edition) applications.
Read-Modify-Write applications read one or more data objects, compute some new value for those objects based on their previous values, and then write out the new value. Examples include document editors (e.g. Word and Excel) and any applications that maintain statistics, such as web sites that record the number of visitors or page clicks.
Generate-Write applications write data objects without reading them. These are often called “blind” writes. The data being written may come from external sources like users or sensors. Examples include creating new files or data objects, appending records to a log, or depositing checks in a banking application.
Let’s consider each of these paradigms and the effect of eventual consistency on applications and application developers that use them.
Read-Display
For Read-Display applications, eventual consistency simply means that users may be presented with stale data since the application may read old values for data objects or the information that is displayed may be missing recently added objects. In Facebook, for example, users may not see recent comments or postings from their friends. In an e-mail application, a user may not see some messages that were recently delivered to his inbox. In a shopping cart application, users may find, when checking out, that their cart is missing some items that were previously added or may still contain items that were added but then removed.
But how does this affect the application developer? The code that he writes to read data from the storage system is the same regardless of whether that storage system provides strongly consistent or eventually consistent answers to read requests. The code to display this data is also independent of the consistency guarantees provided by the storage system, though if the application is informed that it read stale or “tentative” data then it could potentially issue a warning of some sort to its user.
Basically, Read-Display application developers ignore the consistency of the data that is read and displayed; the burden of dealing with inconsistent data is placed on the end users.
Read-Modify-Write
Applications with Read-Modify-Write sequences, generally want to read up-to-date data before performing updates that depend on it. Reading eventually consistent data can produce inaccurate results. For example, consider a web site that maintains click counts. It reads the current count, adds one to it, and then writes out a new value. If the read operation returns stale data, then the new value written will fail to record some clicks. That could lead to lost advertising revenue.
However, if the application programmer knows that he is dealing with an eventually consistent storage system, it is hard to imagine how he could change his code to account for this. Essentially, the developer needs to select a storage system that provides stronger guarantees. Some storage systems offer a choice of consistency guarantees, possibly including guarantees that lie between strong and eventual consistency, such as timeline consistency and bounded staleness. For the example of recording click counts, a read-my-writes guarantee will likely be sufficient since all of the writes come from a single client.
Even strongly consistent reads may be inadequate if different clients are concurrently performing Read-Modify-Write sequences. In this case, race conditions, where two clients read a value and then issue conflicting writes, may lead to incorrect results. Two solutions are used in practice. One is to obtain a lock on an object before reading and writing it, perhaps indirectly through a transaction mechanism. Locking is problematic in an eventually consistent system since clients may disagree on who holds which locks. Using a central lock manager (or a distributed locking protocol) yields consistent locking, but does not alleviate the need for strongly consistent reads.
Another option is to use optimistic concurrency control, i.e. conditional writes. That is, each write operation has a precondition that checks whether the version being overwritten is the same as the version that was previously read and was used as the basis for the write; the write succeeds only if the precondition is met. If a write fails, the application must re-execute the Read-Modify-Write code sequence. Some eventually consistent storage systems allow clients to read from any replica but require write operations to be performed at a designated primary replica. In such systems, optimistic concurrency control can be effective, even for eventually consistent reads. Since all writes go to the primary, the primary holds strongly consistent data and checks each write’s precondition against this data. This prevents conflicting writes. The same code that a developer writes to prevent race conditions in a strongly consistent storage system can be used with an eventually consistent storage system. The main difference, in practice, is that conditional writes are more likely to fail if based on eventually consistent reads. Essentially, reading old data in an eventually consistent system is the same as reading up-to-date data from a strongly consistent system but waiting a long time before issuing a write that depends on this data.
Note that for eventually consistent systems in which any replica can accept write operations, i.e. “update anywhere” schemes, two replicas may accept conflicting updates even if conditional writes are used. In such systems, additional steps are needed to resolve conflicting operations after-the-fact. Conflict resolution may be a burden placed on end users, may be handled automatically by the storage system using built-in policies such as last-writer-wins, or may require developers to produce application-specific resolution code, such as Bayou’s mergeprocs or Coda’s resolvers.
In summary, Read-Modify-Write application developers need not write code to read, modify, and write data objects any differently when using an eventually consistent storage system, but they may need to write additional conflict resolution code.
Generate-Write
Generate-Write code sequences, by definition, do not perform any reads. Thus, they cannot possibly be affected by the read consistency model. Thus, the application code should be independent from the consistency that is provided by the storage system.
However, application developers may need to be concerned about conflicting writes. In general, application-specific integrity constraints may need to be enforced even for applications that perform blind writes. For example, concurrent attempts to create two different files with the same name or two different data objects with the same primary key should be disallowed. In a strongly consistent storage system, or an eventually consistent system where writes are performed at a single primary, the system can easily enforce integrity constraints. The first of a set of conflicting writes will succeed, and the others will be rejected. In an eventually consistent system with an “update anywhere” or “multi-master” model, programmers may need to provide conflict resolvers, as previously discussed.
Whether or not conflict resolution is required depends on how the storage system propagates and performs updates. For example, consider an application that appends log records to a file. Suppose that the system provides a special Append operation. The application does not need to read the file before appending to it; it simply needs to issue append operations. But what happens if two clients are concurrently appending to the same file and their append operations are performed at different replicas? Do these clients need to provide conflict resolution procedures in order to ensure that the replicas eventually hold identical file contents? It depends. If replicas immediately perform the append operations that they receive directly from clients and then later exchange their file contents with other replicas, then undoubtedly a resolver will be needed to resolve the contents of conflicting files. On the other hand, if replicas maintain and exchange operation logs, if they agree on the order of the operations in their replicated logs, and if they perform operations in log order (which may require rollback/redo for operations that arrive out-of-order as in Bayou), then no conflict resolution code is required for Generate-Write applications. Similar scenarios arise for storage systems that provide Increment and Decrement operations, as might be used by a banking application.
Summary
Examining three commonly used data access paradigms indicates that application code changes very little, if at all, when using an underlying storage system that provides eventual rather than strong consistency. The correctness of the program, however, may indeed be affected by the delivered read consistency. And programmers may need to devote time to understanding how eventual consistency impacts the application’s behavior and correctness. If the storage system offers a choice of consistency guarantees, then developers need to choose wisely.
Although conflict resolution is often cited as one of the inherent costs of eventual consistency, dealing with concurrent updates is required even in clients of strongly consistent storage systems. Optimistic concurrency control using conditional writes can be effective for both strongly and eventually consistent systems that use a primary update model. Only in cases of multi-master updates do developers need to write conflict resolvers (or perhaps produce code that asks users to manually resolve conflicting versions).

Recent Comments